The Cross-Facility Federated Learning (xFFL) framework aims to bridge this compute divide. It allows data scientists and domain experts to efficiently exploit multiple independent data centres for extreme-scale deep learning tasks.
The Cross-facility Federated Learning framework
In a decade, AI frontier research transitioned from the researcher’s workstation to thousands of high-end hardware-accelerated compute nodes. This rapid evolution shows no signs of slowing down in the foreseeable future. Obtaining and efficiently exploiting computing resources at that scale is a daunting challenge for universities and SMEs.
Cross-Facility Federated Learning is an experimental distributed computing methodology designed to explore three main research directions:
- Using High-Performance Computers (HPCs) as an enabling platform to train and fine-tune foundation AI models;
- Exploiting the aggregated computing power of multiple HPCs through a Workflow Management System (WMS) to solve today’s large-scale problems (e.g., training trillion-parameters models);
- Federated Learning (FL) as a technique for virtually pooling different datasets while keeping each one private to its owner(s).
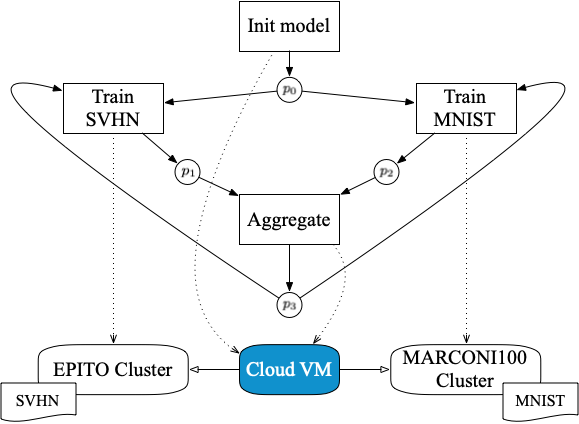
The xFFL workflow is based on a previous small-scale experiment that described the federated training of a VGG16 model across the CINECA MARCONI100 HPC facility (Bologna, Italy) and the HPC4AI OpenStack cloud (Torino, Italy). Thanks to the flexibility offered by StreamFlow, this approach is general enough to be reused in the xFFL experiments on a larger scale.
To our knowledge, xFFL is the first experimental attempt to train a foundation model through a cross-facility approach on geographically distant HPCs. To learn more about the methodology and its development, visit the official xFFL web page or explore the GitHub repository.
StreamFlow application
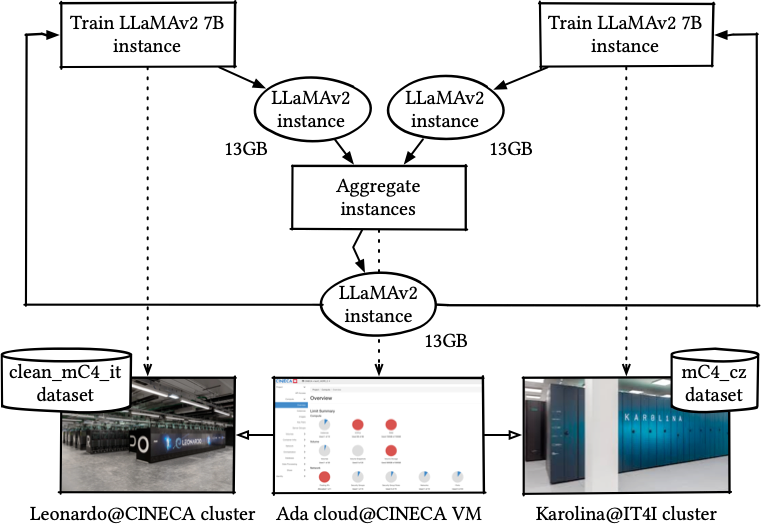
The first iteration of the xFFL experiment trained the LLaMA-2 7 billion model, exploiting two EuroHPC supercomputers cooperatively: CINECA Leonardo (Bologna, Italy) and IT4I Karolina (Ostrava, Czech Republic). Since those two infrastructures are located in two states speaking different languages, such an experiment aims to train a single bilingual model using two distinct language corpora.
The FL protocol is described by a cyclic workflow expressed through the Common Workflow Language (CWL). The xFFL workflow execution is managed by a StreamFlow instance running on a VM hosted on the CINECA ADA cloud (Bologna, Italy).
StreamFlow offloads SLURM jobs with input data (aggregated LLaMA model) to be submitted to the different supercomputers. Then, it gathers the jobs’ results (a set of LLaMA models, each trained on a different supercomputer) for the aggregation step. Aggregation is performed locally on the ADA cloud VM. Training and validation datasets remain stored on the owner’s infrastructures and never move.
In our experiments, queueing times were negligible for up to 32 nodes but increased to over 7 minutes for 128 nodes. However, execution times were orders of magnitude higher, ranging from 774 (on two nodes) to 14 (on 128 nodes) hours. Also, other sources of overhead, i.e., data transfer and model aggregation times, do not exceed hundreds of
seconds, making them negligible compared to the tens of hours each training round needs.
Therefore, despite showing excellent strong scaling, training times offset queuing times and transfer overhead even for large amounts of computing power. This result makes it perfectly feasible to separate different training rounds into multiple job submissions without significantly impacting the overall performance.
I. Colonnelli, R. Birke, G. Malenza, G. Mittone, A. Mulone, J. Galjaard, L. Y. Chen, S. Bassini, G. Scipione, J. Martinovič, V. Vondrák, and M. Aldinucci, “Cross-Facility Federated Learning,” in Procedia Computer Science, vol. 240, p. 3–12, 2024. doi:10.1016/j.procs.2024.07.003